Engineering 5 min read
TurboQuant Explained: How Google Cuts LLM Memory by 6x Without Losing Accuracy
RM
RepoMind Engineering
March 26, 2026

TurboQuant is Google Research’s new compression method for LLM KV cache memory, promising 6x lower memory use, up to 8x faster attention, and little to no accuracy loss.
Most AI headlines chase bigger models, bigger training runs, and bigger GPU clusters.
TurboQuant points in the opposite direction.
Instead of making large language models larger, Google Research is focusing on making them leaner during inference, especially when handling long prompts and long conversations. TurboQuant is a new compression method designed to shrink one of the biggest hidden memory hogs in modern LLMs: the KV cache. Google says it can compress KV cache data down to roughly 3 bits, reduce memory use by at least 6x, and in some benchmarks deliver up to 8x faster attention on Nvidia H100 GPUs, all while preserving model quality.
That makes TurboQuant more than just another optimization trick. It hints at a future where AI systems become cheaper to serve, more scalable at long context lengths, and less dependent on brute-force memory expansion.
First, what is the KV cache?
To understand TurboQuant, you need to understand the problem it targets.
When an LLM processes text, it uses attention to relate the current token to earlier tokens. Recomputing all that from scratch for every generated token would be painfully expensive, so the model stores intermediate attention information from earlier tokens in memory. That stored memory is the key-value cache, or KV cache. As prompts and conversations grow longer, this cache grows too, and it can become a major bottleneck for latency, throughput, and GPU memory usage.
In plain English, the KV cache is the model’s working notebook. It helps the system remember what it has already processed, but the notebook keeps thickening with every page.
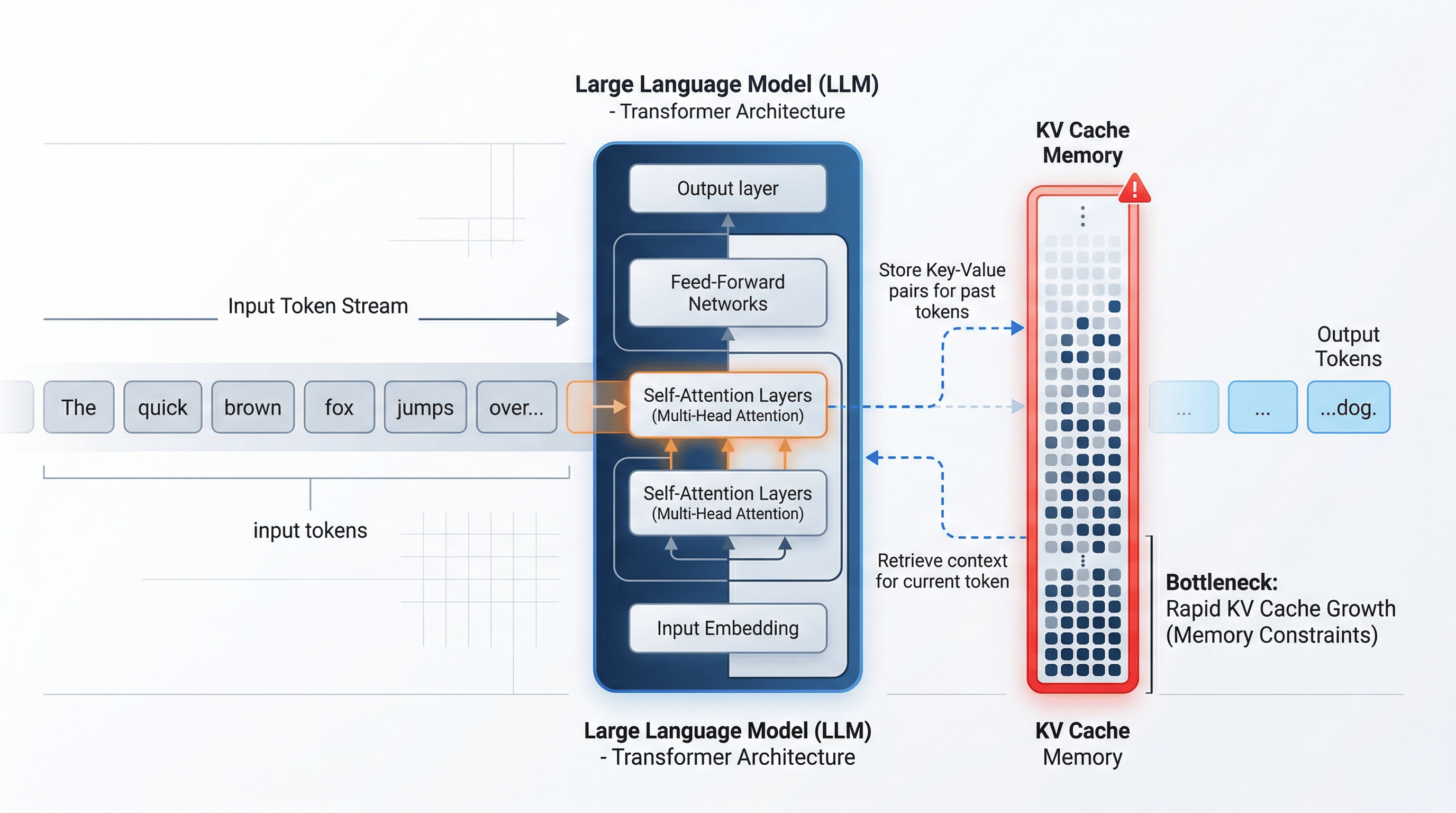
Why KV cache matters more than people think
A lot of people assume model size is the main memory problem in AI. That is true during loading, but inference-time memory is a different beast.
Even if you already have the model weights loaded, serving long contexts can still become expensive because the KV cache grows with the sequence. This is especially relevant for chatbots, coding assistants, document summarizers, and retrieval-heavy applications that feed models long histories or large files. Google positions TurboQuant as a response to exactly this growing inference bottleneck.
This is why TurboQuant matters. It attacks the memory that grows while the model is actually being used, not just the static weight file sitting on the GPU.
So what exactly is TurboQuant?
Google Research describes TurboQuant as a training-free online vector quantization algorithm built for extreme compression in AI systems, especially for KV-cache compression and vector search. Unlike many compression methods that require retraining or fine-tuning, TurboQuant is designed to work online, which makes it practical for real inference pipelines.
The core pitch is simple:
- compress KV cache far more aggressively
- avoid the usual quality collapse
- keep runtime overhead low enough to be useful in production
That combination is the interesting part. In AI, compression is rarely just about shrinking numbers. It is about shrinking them without shredding the meaning those numbers carry.
How TurboQuant is different from ordinary quantization
Standard quantization usually reduces precision by storing values in fewer bits, such as moving from FP16 to INT8 or 4-bit formats. That saves memory, but it often introduces tradeoffs. Accuracy can degrade, and some methods need extra metadata like normalization constants or scaling factors that eat into the savings.
TurboQuant tries to dodge that trap.
According to Google and reporting that summarizes the method, TurboQuant combines two ingredients:
- PolarQuant, which maps vectors into polar-style representations to avoid some per-block normalization overhead
- A 1-bit Quantized Johnson-Lindenstrauss layer, or QJL, which acts as an error-correction mechanism for the compression residue
Think of it this way: traditional quantization makes the notes smaller. TurboQuant makes them smaller and leaves behind a tiny correction whisper so the model can reconstruct what matters.
That is why the reported numbers have turned heads. This is not just “a bit smaller.” It is a serious squeeze.
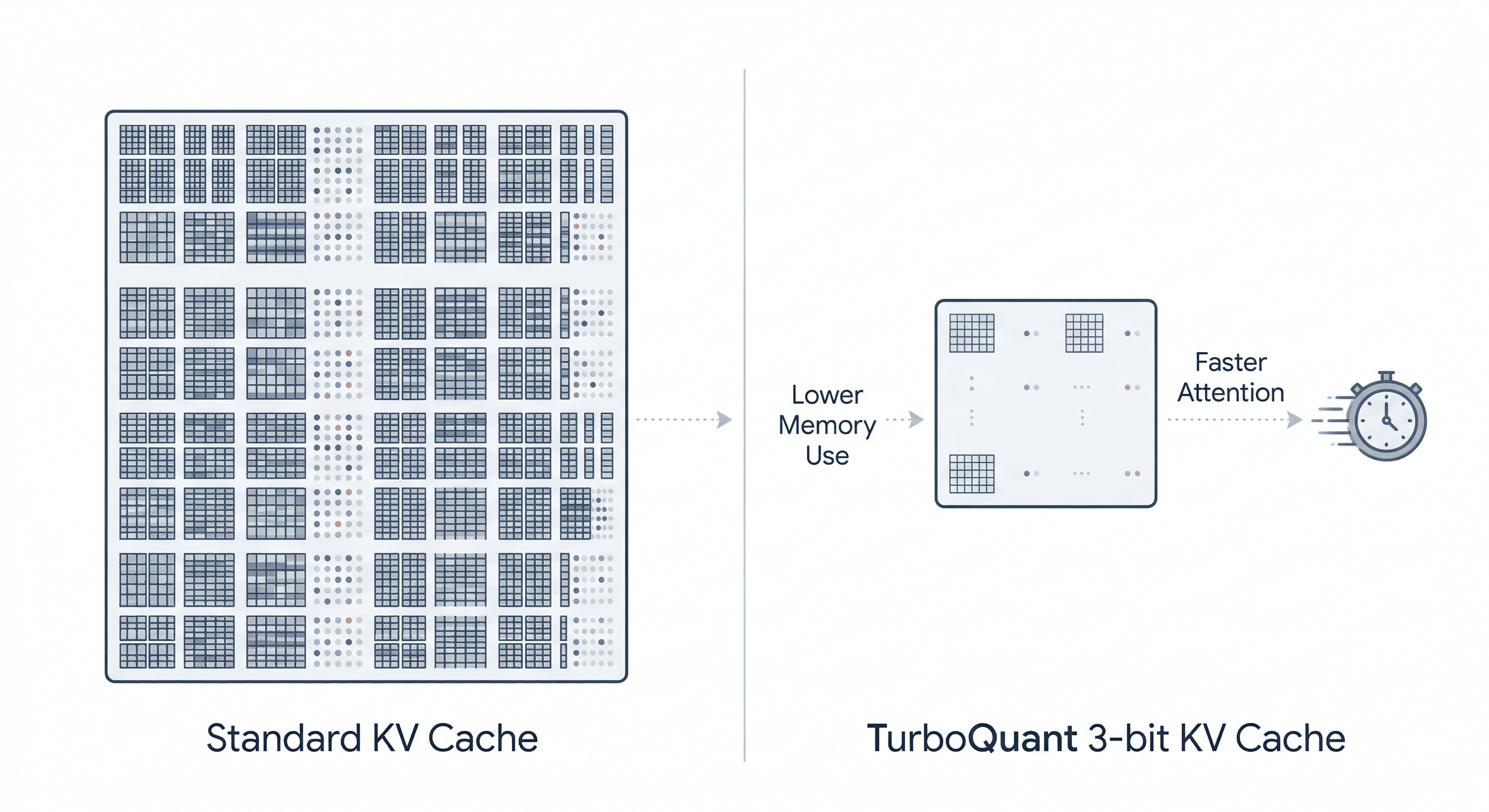
What do the benchmarks suggest?
Google says TurboQuant achieves zero-accuracy-loss 3-bit KV-cache compression in the settings highlighted in its launch materials, with at least 6x lower memory use and up to 8x faster attention on H100 GPUs in some experiments. Coverage of the release also notes strong benchmark results across evaluations such as LongBench, Needle in a Haystack, and L-Eval with Gemma and Mistral-family models.
As always, benchmark caveats matter. “Up to” numbers are not universal laws of physics. They depend on model architecture, hardware, context length, implementation quality, and the exact workload. But even with that caution tape in place, the result is still striking: Google is claiming that extreme KV-cache compression does not have to mean obvious model degradation.
Does TurboQuant compress the whole model?
No. This is an important distinction.
TurboQuant is mainly about compressing the KV cache during inference, not about permanently shrinking the model’s full weight parameters into a tiny file for local deployment. That means it does not magically turn a very large model into something that fits everywhere. What it does is make long-context inference much more memory-efficient once the model is already running.
So if model weights are the ship, TurboQuant is not reducing the size of the shipyard. It is reorganizing the cargo hold while the ship is at sea.
Why the industry noticed so fast
TurboQuant landed with more than academic interest. The announcement quickly fed into discussions about AI infrastructure economics, especially memory demand. Some market coverage reported that memory-related semiconductor stocks reacted after the news, because any technique that sharply lowers memory requirements can change assumptions about what AI systems need at scale.
That does not mean one research announcement instantly rewrites the hardware market. But it does reveal something important: AI efficiency research is no longer a side quest. It is starting to shape product economics, infrastructure strategy, and investor narratives.
What TurboQuant could mean in practice
If the technique holds up in broad deployment, the implications are substantial.
For AI companies, it could mean:
- serving more requests per GPU
- supporting longer context windows more affordably
- reducing memory pressure during inference
- improving throughput for long-context applications
For developers, it could mean:
- more room to experiment with long-document workflows
- better economics for chat and coding agents
- fewer painful tradeoffs between context length and serving cost
For the broader AI landscape, it reinforces a growing theme: the next wave of breakthroughs may come less from raw parameter inflation and more from smarter systems engineering, memory optimization, and inference efficiency.
The bigger story behind TurboQuant
TurboQuant is easy to frame as a compression trick, but that undersells it.
The real story is that modern AI is hitting bottlenecks that are no longer purely about intelligence. They are about bandwidth, memory, cost, and deployment constraints. The frontier is not only “Can the model do this?” but also “Can we afford to do this at scale, in real time, for everyone?”
That is where methods like TurboQuant become strategically important.
They do not make the AI look flashier in a demo reel. They make it more deployable in the real world. And that is often where the true leverage lives.
Final thoughts
TurboQuant matters because it targets one of the least glamorous but most expensive parts of modern LLM deployment: memory growth during inference.
If Google’s claims continue to hold across implementations, TurboQuant could become one of those behind-the-scenes advances that quietly changes the economics of AI. Not by making models louder, but by making them lighter.
And in a field obsessed with giant machines, sometimes the sharpest breakthrough is a better suitcase.
Here is the official article from google, in case you want to deep-dive into it: https://research.google/blog/turboquant-redefining-ai-efficiency-with-extreme-compression/
If you’re building with LLMs, TurboQuant is worth watching closely. The next era of AI may belong not just to the biggest models, but to the ones that waste the least memory.